
Forward resolution is the process of taking a name (e.g. coconaut.avax) and a desired type of value (e.g. C-Chain address) and returning the related value. Reverse resolution is the process of taking a value (e.g. C-Chain address) and returning a name (e.g. coconaut.avax). This document will cover our proposed architecture for implementing this functionality.
Forward Resolution will make use of two contracts:
A user looking to perform a Forward Resolution would use the following process:
A user looking to set up Forward Resolution for a name they control would use the following process:
The following diagram demonstrates potential communication for a Forward Resolution.
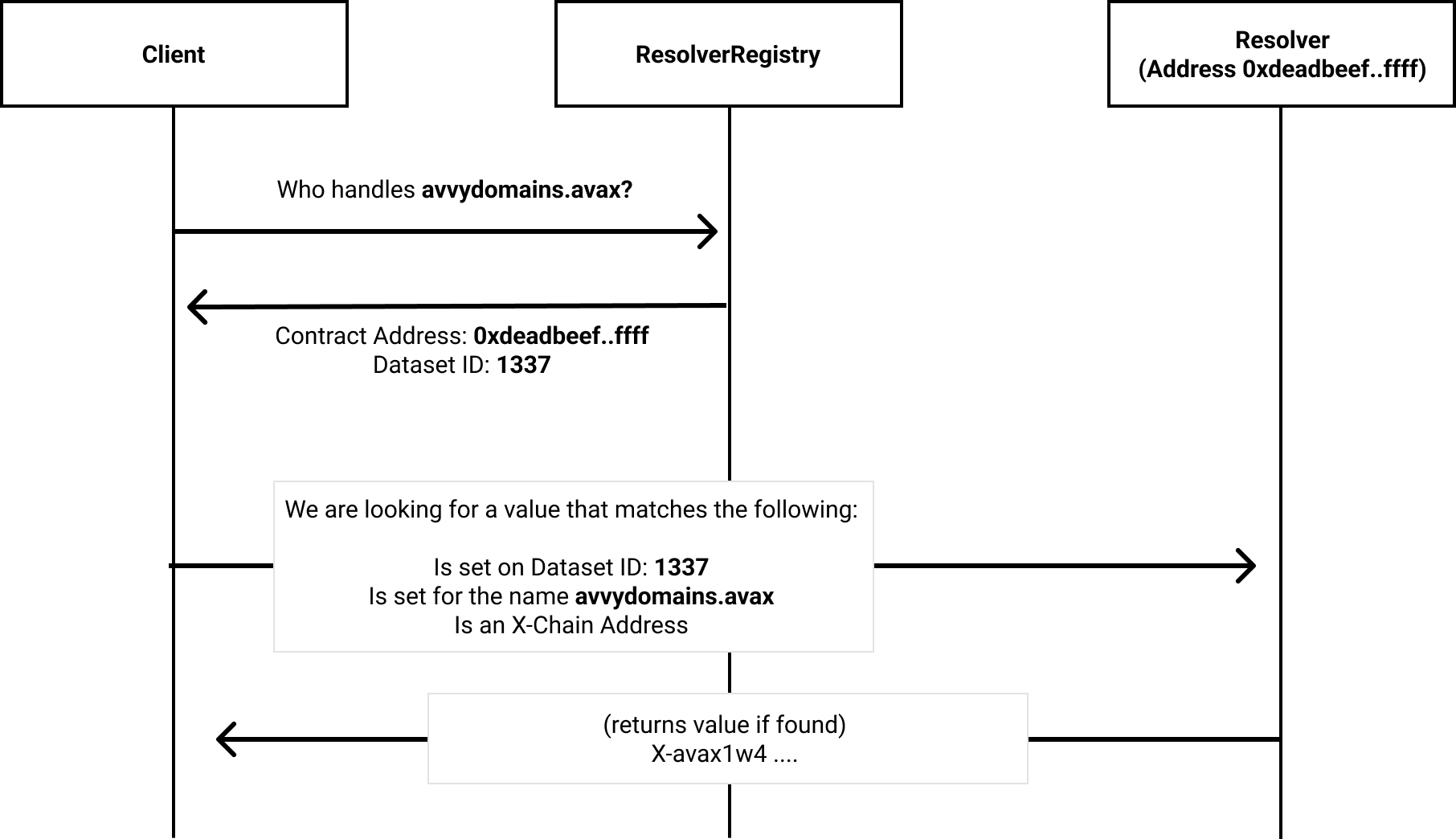
If a client desires to resolve a record on alpha.beta.charlie.avax, the client cannot know which level of the domain will have an entry in the ResolverRegistry. Clients should iterate up levels of subdomains until they discover an entry in the ResolverRegistry.
How should Resolvers index their data? We perform lookups based on names (for example, avvydomains.avax, or subdomain.avvydomains.avax), so naturally one would think the indicies should be those names. One drawback of this method is that we reveal the names themselves. In some cases, it may be advantageous to keep a name hidden.
We propose using unique Dataset IDs, which are disjoint from the names themselves. This provides flexibility for Resolvers in managing ownership of datasets, authentication of changes, etc.
When performing a Forward Resolution, a user will present a name (e.g. coconaut.avax) as well as the data type they wish to receive. We will refer to this data type as the key.
We consider two scenarios for use of the application. The first relates to standardized value types which the community will work together to agree upon. Some examples of potential standardized value types include C-Chain Addresses, X-Chain Addresses, DNS records such as CNAME and A records, generic communication information such as email addresses, etc. The second use-case is as an abstract data-storage solution, where users may develop their own use-cases.
We propose the following differentiation between keys:
Resolvers would be required to implement two methods relating to resolution: one for resolving Standard Keys, and one for resolving Custom Keys.
We propose two methods for Forward Resolution:
(where resolveStandard is for Standard Keys, and resolve is for Custom Keys).
We propose that the hash used for retrieving data from resolvers be a one-way hash of (i) the namehash of the desired subdomain; and (ii) the DatasetID. This one-way hash should not cause hash collisions with other subdomains.
Why is this useful? First, it allows us to keep the hash of sub.avvydomains.avax private, if we want, while still allowing us to perform a lookup. Second, it allows Resolvers to keep Datasets separate (e.g. allowing sub.avvydomains.avax to resolve different values in Dataset 1337 and in Dataset 8888). This is useful for Privacy Considerations and Data Clearing.
What privacy desires might users have? Consider a user who wants the utility of forward resolution, but has a number of wallets that they want to keep relatively private.
We have a few information targets which we want to keep in mind:
Associating a domain name with a wallet
Associating a domain name with the wallet which owns the domain name can leak information. For example, if my name is johndaviddoe.avax and I hold that name in my wallet, observers may be able to associate my wallet address with my name. We use the concept of Enhanced Privacy, to mitigate this risk.
Associating a wallet with data that is set on the Resolver
Let's say you have two private C-Chain wallets and you do not want to create observable links between these wallets. You register utilityname.avax from wallet #1, to keep track of the names. You wish to have wallet1.utilityname.avax resolve to wallet #1 and wallet2.utilityname.avax resolve to wallet #2.
We propose the following method for keeping these subdomains private:
This method is brainstormed and may have flaws. If you have comments, please join our Discord or Telegram to share.
This is likely a rare use-case, but we believe it to be important. To achieve this level of privacy, users will sacrifice the ability to enumerate subdomains.
Why must we use a custom resolver? Each subdomain has a unique hash. On shared contracts, we must authenticate the user setting the hash. To authenticate the user, the user sends the hash, as well as the preimage for the subdomain. Using this information, we can calculate the hash of the subdomain, but also authenticate the user as the owner of the domain. This method unfortunately discloses the subdomain, which is also our encryption key in this method. By using a custom resolver, we do not need to authenticate the user. The user simply needs to configure the ResolverRegistry such that resolution requests for their domain are directed to their custom contract.
Let's consider the following scenario: User A is the current registrant of toast.avax, and sets a record burnt.toast.avax. User B later acquires toast.avax, but isn't aware of burnt.toast.avax, which continues to resolve. There are a number of scenarios where this could be a large problem, and so it becomes important for User B to be able to clear the data on toast.avax after acquiring the name.
Clearing data requires the following steps:
To accomplish this, we require that the ResolverRegistry offer the ability to enumerate registry entries for toast.avax and all of it's subdomains. A user can then discover which Resolvers are in use, and make the appropriate changes.
We must also consider the scenario where a domain has transferred to a new owner, and that new owner has not yet investigated the entries which are set on the domain. We should allow clients of the system to identify this situation.
To facilitate these requirements, the following must be true:
In this process, we wish to map a value to a name. When setting up reverse resolution, we must show that the owner of the name is also the owner of the value (since the value can only map to a single name). We must authenticate ownership, otherwise we can have malicious or unintentional errors.
The process of authenticating ownership will differ dependent on record type. In the case of reversing a c-chain address to a name, solidity will take care of the authentication for us (we can simply check tx.origin or msg.sender). With other record types, the process becomes more difficult (Validator NodeIDs, X-Chain addresses, etc).
Many record types will require custom contracts for reverse resolution. We hope to abstract the process to achieve general goals, primarily, the goal of being able to reset data when names are transferred between owners.
We propose using the ResolverRegistry to identify the ReverseResolvers for given record types. Each Standard Key can have a ReverseResolver. For Custom Keys, developers seeking custom functionality can launch their own ReverseResolvers, however they would not be able to add them to the ResolverRegistry.
Clearing data is simpler in the case of Reverse Resolution. We are able to enumerate the set of Standard Keys, to discover the set of ReverseResolvers. Each ReverseResolver should offer either a clearData(name) method which attempts to scrub all records relating to a name, or a method of enumerating records for a given name (so they can be modified or removed).
